
InfiniteTalk:开源AI数字人视频生成框架

一、核心功能
InfiniteTalk是一款由美团视觉智能部开发的开源AI工具,专注于数字人视频生成。其核心能力包括:
-
多模态输入支持
- 支持音频/歌曲+图片/视频的双输入模式
- 实现图像到视频(Image-to-Video)和视频到视频(Video-to-Video)的转换
-
高级同步技术
- 无限时长口型同步
- 全身情感表达控制
- 保留源视频的背景与摄像机运动
-
应用场景覆盖
- 人物对话视频生成 - 音乐对口型表演 - 静态图片动态化
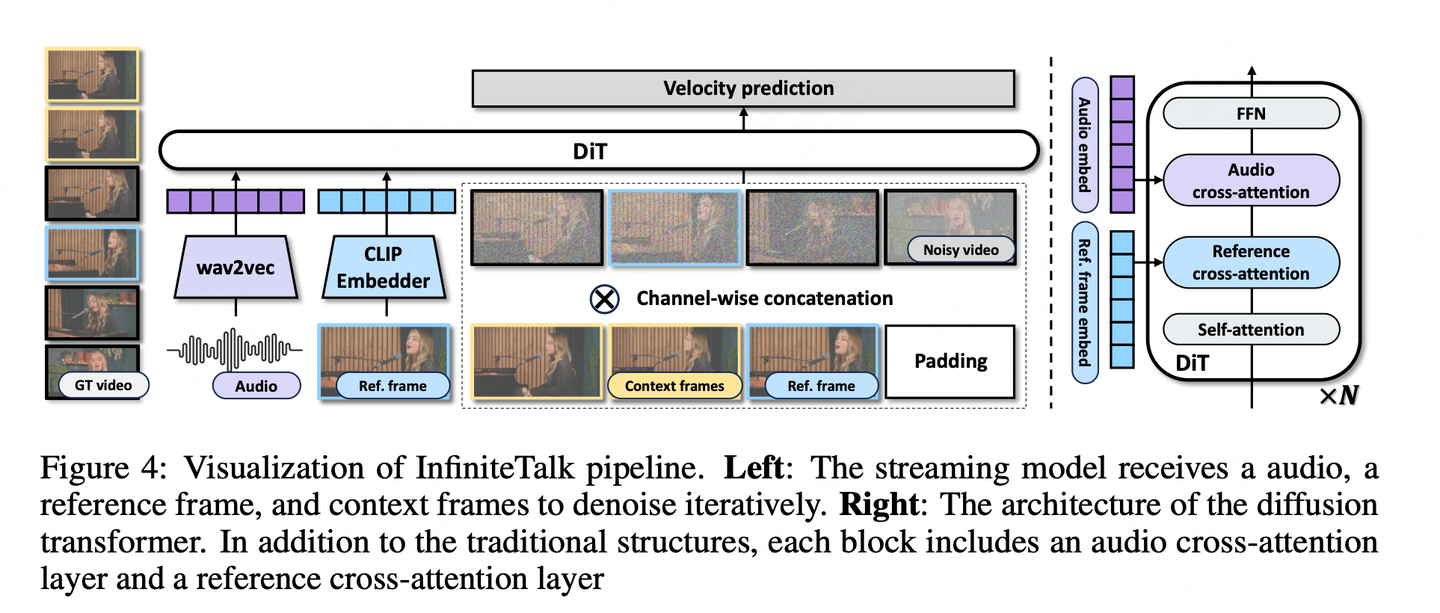
二、技术特性
-
架构设计
- 基于ComfyUI工作流
- 采用稀疏帧视频配音技术(Sparse-frame video dubbing)
- 支持全身运动编辑(非仅限于嘴部区域)
-
性能要求
配置项 最低要求 推荐配置 显存 8GB 12GB+ 输入分辨率 512×512 1024×1024 输出帧率 25fps 60fps -
控制维度
- 通过文本提示词控制人物动作
- 情绪参数调节系统
- 音色管理系统(支持自定义声纹)

三、使用流程
-
基础操作
1. 上传音频文件(MP3/WAV格式) 2. 添加图像或视频素材 3. 设置生成参数(分辨率/帧率等) 4. 启动渲染 -
高级功能
- 背景替换与动态遮罩
- 多人物同场景交互
- 实时预览与参数微调
四、开发资源
- 代码仓库:
👉 GitHub - MeiGen-Al/InfiniteTalk - 技术文档:包含ComfyUI节点说明与API接口文档
- 预训练模型:提供基础形象与动作库
该框架通过Apache 2.0协议开源,当前已获得2.2k星标。其创新性的长序列生成能力突破了传统数字人视频的时长限制,特别适合虚拟主播、在线教育等场景。建议从"图像+音频"基础模式入手,逐步探索视频重定向等进阶功能。