
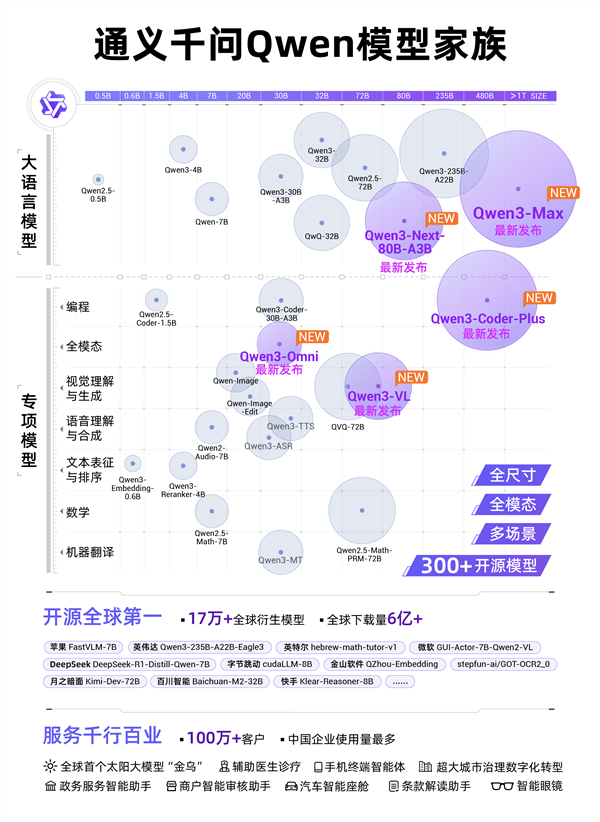
一、架构创新
阿里巴巴通义千问团队最新发布的Qwen3-Omni大模型采用Thinker-Talker双模块架构:
- •
Thinker模块:专注多模态信息的深度推理与融合
- •
Talker模块:专攻流式语音生成
这种分工设计显著优化了计算资源分配,将端到端音频对话延迟压降至211毫秒,同时支持30分钟长音频理解。
二、性能表现
该模型在36项权威基准测试中斩获:
- •
32项开源最佳
- •
22项总体第一
特别在保持文本/图像处理能力的同时,强化了音频/视频模态处理,实现业界罕见的"全模态不降智"效果。
三、技术亮点
markdown
复制
四、局限与挑战
|
优势 |
当前局限 |
|---|---|
|
多模态协同 |
极端长视频处理不足 |
|
低延迟交互 |
低分辨率视频识别受限 |
|
中文场景优化 |
完全版需高性能计算支持 |
资源:https://help.aliyun.com/zh/model-studio/qwen-omni
👉 通义千问官方仓库
该模型通过架构创新突破多模态协同瓶颈,其"思考-表达"分离设计为AI交互提供了新范式。开发者可重点关注音频处理模块的API设计,企业用户建议从会议系统等实时性要求高的场景切入验证。